Marketing goals can be defined as broad, long-term outcomes that a company wants to achieve via marketing efforts.
Setting clear marketing goals is important, as this can effectively focus your team on a shared vision. But the thing is, you need to choose your goals carefully. Otherwise, you may waste a lot of time on things that bring poor results or even undermine your past efforts.
In this article, we’ve curated a short list of strategic goals that are worth considering in any marketing strategy, along with some ideas on how you can measure them:
- Improve product satisfaction
- Grow organic traffic
- Generate leads
- Establish thought leadership
- Increase brand awareness
- Increase revenue
Any successful marketing needs to be founded on a good product that satisfies existing market demand. Otherwise, none of your marketing efforts will “stick.” Meaning, no matter how you promote the product, you will fail to convince your audience and build sustainable growth.
Conversely, a product that users are willing to use, buy, and recommend to others will reinforce all marketing activities. In fact, a lot of successful companies have grown solely or mainly via word-of-mouth recommendations sparked by the remarkable value of their products (e.g., Whatsapp, Tesla).
To set yourself on the right path of improving product satisfaction, you need to achieve product-market fit.
Once you know you’re in the right market with the right kind of product, you can start delighting your users with useful features and a great user experience. Keep in mind that even seemingly simple product improvements can go a long way.
We have finally released this long overdue SEO metric:
? Traffic potential ?
Because pages don’t rank in Google for just a single keyword. They also rank for all the different variations of that keyword and get search traffic from them. https://t.co/a0ehTT5WJV pic.twitter.com/zQAXCaQTYj
— Tim Soulo (@timsoulo) November 12, 2021
How to measure
You can measure product satisfaction in two ways: ask your users what they think or gather relevant data from product usage.
Surveys
In surveys, you should ask all kinds of questions that help you understand how well your product satisfies users’ needs. You can also use tried and tested methods like the popular and uncomplicated Net Promoter Score (NPS) survey.
This survey comprises just one question: “How likely are you to recommend [product] to a friend or colleague?” The answers are given on a 10-point scale.

You can find multiple tools online that will help you distribute the survey and calculate your NPS (e.g., Hotjar, Survicate).
Product engagement
If you’re running an online service, consider measuring product satisfaction with product analysis tools (also called product intelligence tools) like Mixpanel or Amplitude. They work by gathering data from your users’ in-app behavior and allowing you to analyze the data to gain insights from it.
For example, by measuring how often your users reach out for particular features inside your product, you can see whether those features bring value or not. Then, you can discard unused features based on real data or conduct experiments (e.g., tweaking your features or making them more visible).
User retention
User retention (or cohort retention) is a metric used for measuring the ability to keep customers over a specified period of time.
If your customers go as quickly as they come, this is usually a huge red flag (with some exceptions, e.g., e?commerce). If you’re not operating in a niche where a short usage period is natural, low user retention is a sign that:
- Users don’t find what you’ve promised in your marketing communication.
- Your product delivers the promise, but your competitors do a better job.
In these scenarios, it’s likely you’re wasting money and brand equity by providing something people are not willing to stay with. So you need to improve your product fast.
That said, even if you have the best product on the market, the so-called customer churn (i.e., when customers stop using your product) is a natural phenomenon to some extent. The key here is to determine whether you have a healthy retention rate.
Organic traffic, also called organic search traffic, refers to the visitors who come to your website via the non-paid search results from a search engine (e.g., Google, DuckDuckGo).
To take advantage of the organic traffic potential from search engines, you need to publish content based on search demand and the business value of a particular topic (the so-called SEO content).
That way, whenever someone searches for a solution via a search engine, they will find your content and, consequently, your brand and product.
Here are the top reasons why you should join the majority of marketers who invest in creating SEO content to grow organic traffic:
- SEO content can influence and even drive the entire marketing funnel.
- Such content brings almost free, continuous traffic.
- Compounding effects. A blog post written years ago can get you traffic now and into the future as long as you rank high.
- How much your organic traffic grows depends more on content quality and creativity rather than budget.
- The flywheel effect: Content marketing done right can be a self-reinforcing mechanism that helps you get results more easily as you go along.
Let me just add that this is not some hypothesis. At Ahrefs, we’ve been systematically developing search engine optimized articles and videos, and the articles alone bring us approximately 384K organic visits every month.
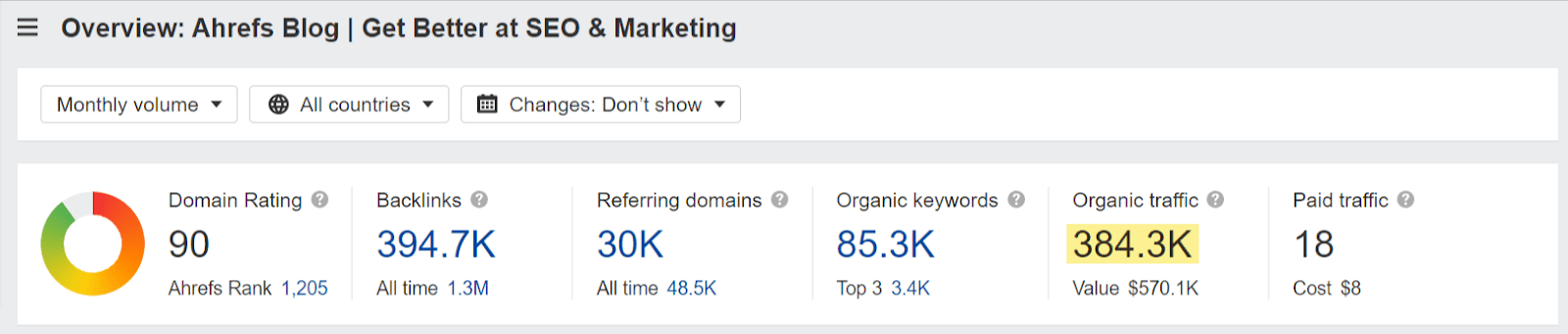
How to measure
We can recommend two types of tools here.
Firstly, measuring organic traffic is best done via Google Search Console (GSC). This is a free tool that gives the most accurate organic traffic data. GSC will show you the number of clicks coming from Google Search, Discover, or News. It’ll also show you the number of times your content has been displayed by Google (i.e., impressions):
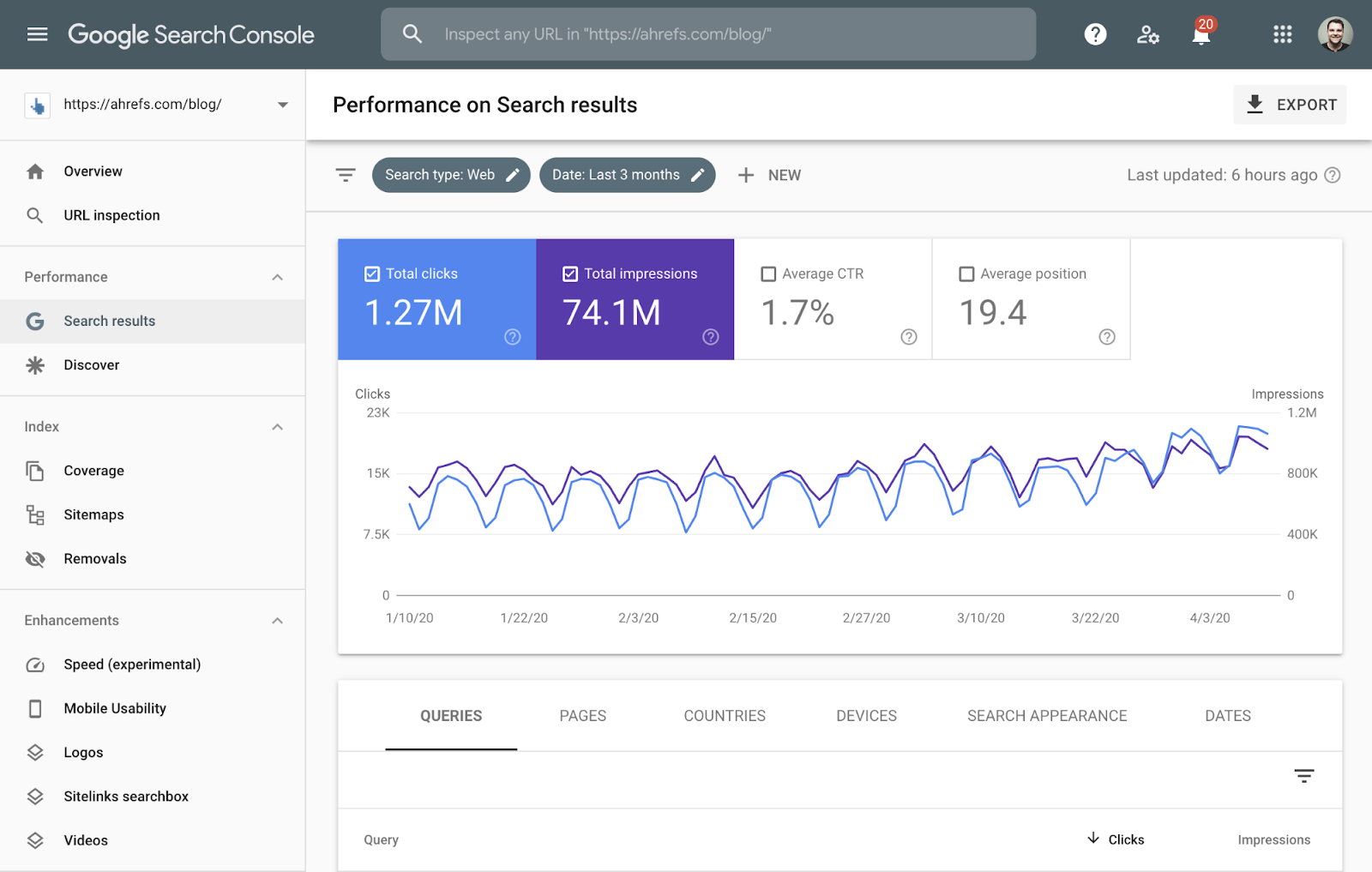
While GSC does a great job of providing these simple metrics, it lacks features and data for comprehensive organic traffic analysis.
This brings us to other types of tools: SEO tools that fill the gaps of GSC, such as the free Ahrefs Webmaster Tools.
For example, while GSC will show you up to 1K keywords and up to 1K backlinks, Ahrefs Webmaster Tools will show you that and many more data points without any limits.
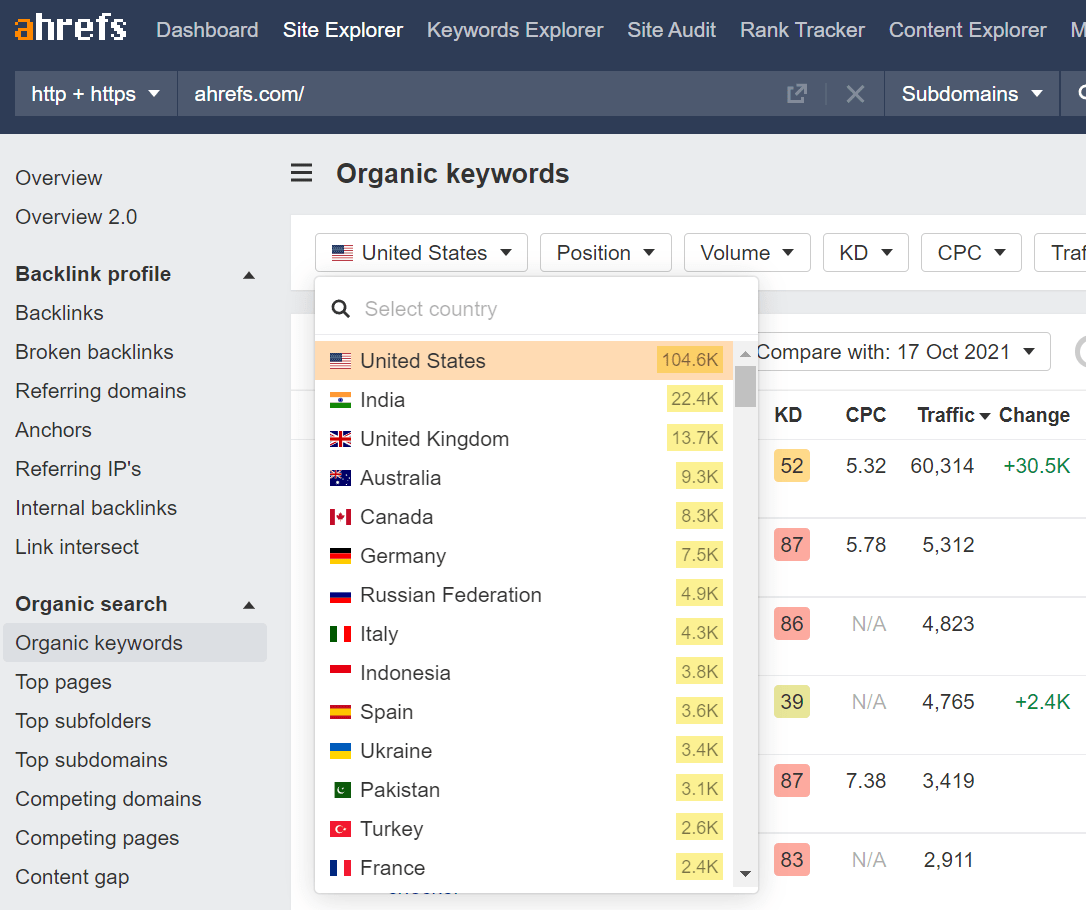
To sum up, you can use GSC for measuring organic traffic and other more advanced SEO tools for SEO analysis and finding growth opportunities.
To put things simply, the more leads you generate, the more revenue you make. This is because every lead is a potential customer. However, not every lead will become a customer, so you need a lot more leads to get your desired number of customers.
A lead is anyone who has expressed interest in a product or service by sharing their contact information (e.g., email address) with a company in exchange for some kind of value (e.g., free ebook, free tool, weekly email newsletter with educational materials).
More often than not, potential customers are not instantly ready to buy. This is especially when they have little or no acquaintance with your brand.
When there is a lot of competition in the market, your potential customers are likely to do some research and compare you to others before they make a purchase. Moreover, if your product is complex and/or expensive, people need to make sure the product will solve their problem or will be worth their money and effort.
This is where lead generation comes in. When a person gives you their contact information, you gain an opportunity to contact them directly in the future. You can use that opportunity to nurture your relationship with them to a point where they are ready to buy.
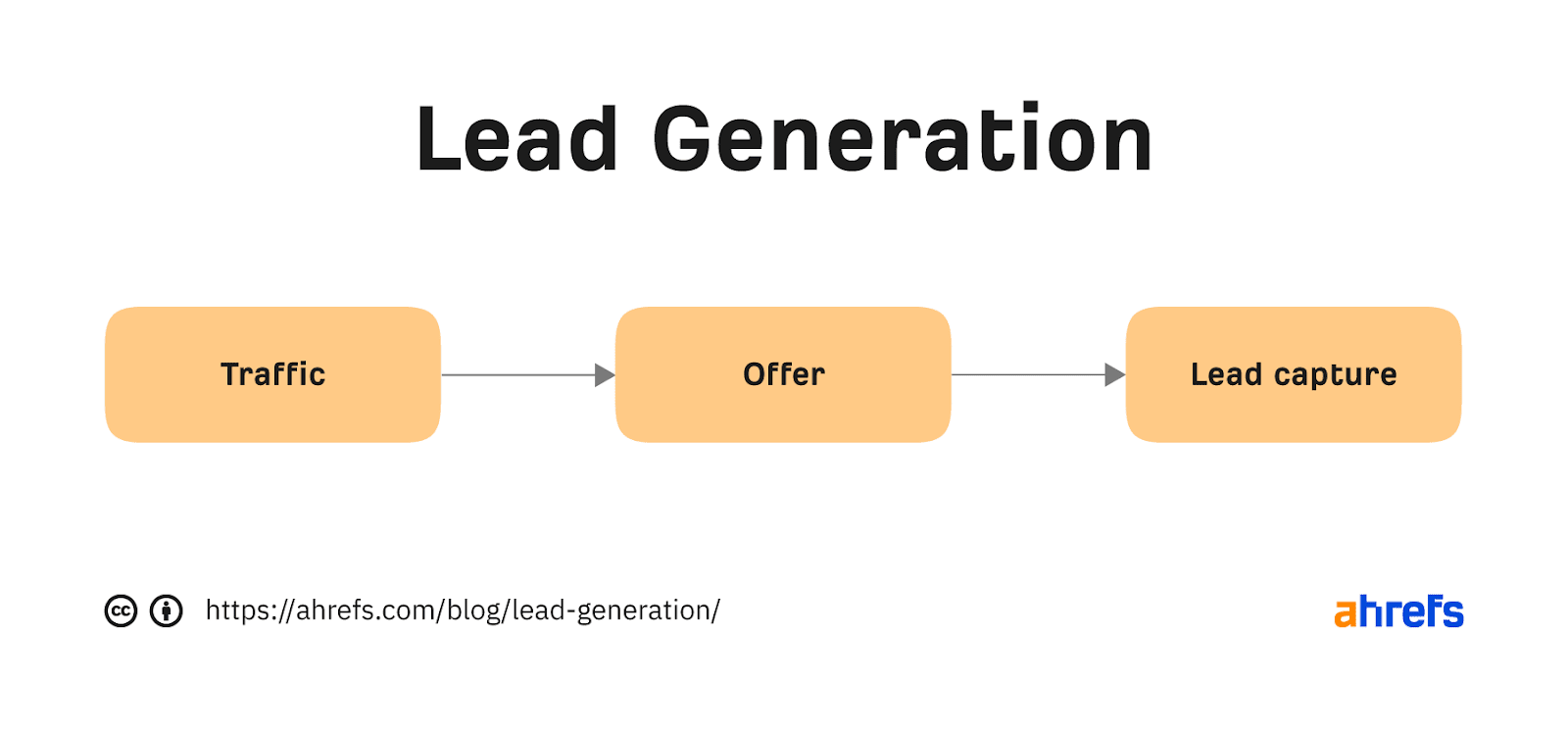
To generate leads, you will need three things:
- Traffic – In other words, visitors coming through your marketing channels.
- Offer – The value you are going to provide in exchange for contact information (e.g., free ebook).
- Lead capture – A form where people can submit their contact information (e.g., name, phone number, email address).
How to measure
How you measure your lead generation depends on your offer. This can be the number of newsletter subscribers, trial sign-ups, app downloads, or whatever else you are planning to provide.
The simplest way to measure incoming leads is via the same tool you use to capture your leads. For example, our email capture form uses Mailchimp’s functionality. It’s the same app we use to monitor the number of leads and send a weekly newsletter to people who signed up.
You can also aggregate your data in a business intelligence software like Google Data Studio or Klipfolio. Then view the data next to other important metrics for quick insights, such as the conversion rate from leads to customers.
In marketing, thought leadership is demonstrating your brand has expertise in its area of business. Effective thought leadership creates a belief among your target audience that your solutions are the best.
Through effective thought leadership, you become an authority in your industry—that status reinforces every message you send out. And so, in the classic conundrum of whether the messenger is more important than the message, you can actually have both.
The more sophisticated and technically oriented the market, the more thought leadership counts. A good example of this is the electric car market. Tesla is an undisputed thought leader in this area. That’s why it surpasses sales of other established car brands with larger advertising budgets. In fact, Tesla is famous for its anti-advertising attitude.
We don’t buy advertising
— Elon Musk (@elonmusk) April 29, 2019
How to measure
Measuring your progress in becoming a thought leader depends on where you share your ideas. Here, we’ll show examples of two effective channels and their respective metrics.
Quality backlinks
A backlink is a link on one website that links to another website. Backlinks act as votes. Even Google thinks so, treating backlinks as one of the most important ranking factors.
And so if you publish content that gets this kind of vote, you’re on the right track of becoming an authority in your industry. This is because people are digitally voting for what you say, resulting in direct traffic from those pages and higher search engine rankings.
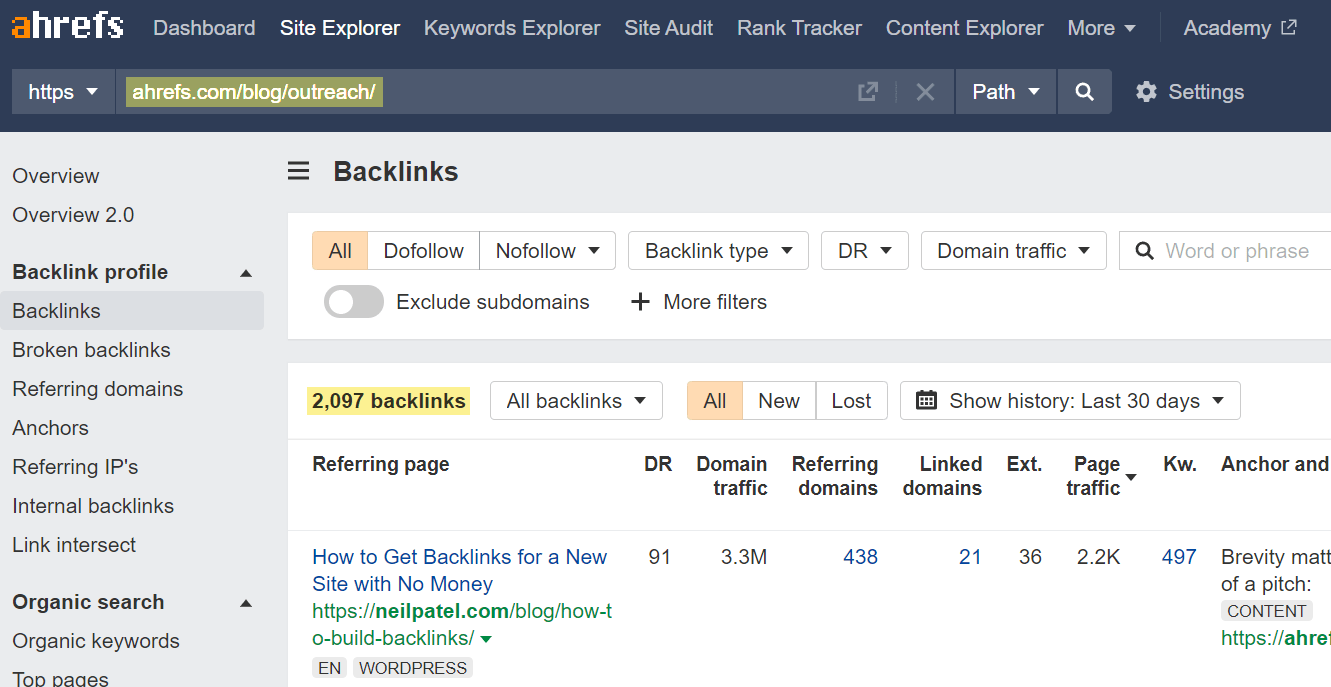
To illustrate, one of the widely discussed subjects in the SEO community is building links through outreach. Our CMO, Tim Soulo, has joined the conversation with an article called I Just Deleted Your Outreach Email. And NO, I Don’t Feel Sorry, which explains how to do effective outreach that doesn’t feel like spam.
That article alone got over 2K backlinks (aka digital votes).
And just a quick reminder—sharing ideas through such articles brings customers:
Speaking engagements
Speaking engagements come in different shapes and sizes. These can be either big industry events like BrightonSEO (with some 4K attendees) or more cozy settings with smaller audiences like podcast interviews.
What they all have in common is getting attention from industry professionals and even industry authorities. So the more you speak at those events, the more likely you are to reach people with your ideas (and your name) and become an authority in your niche.
With speaking engagements, you can put your name on the map, attract followers to your social media channels, and communicate with these followers directly later on.
Once you have more budget, you can even up the ante by creating your own conference, especially if you want to popularize an original concept. That’s what Hubspot has done with the term “inbound marketing” and its INBOUND event.

A brand is a central concept in marketing, and it’s been this way for decades. This is because brands have powerful effects on consumers:
- A brand makes recognizing the product as easy as remembering the word or the shape of a logo.
- A brand evokes associations with positive experiences.
- A brand allows for rationalizing the cost of the product.
Building brand awareness increases the odds of consumers associating your brand or product with a specific need.
Just think about it. Starbucks is one of the most valuable brands in the world. For millions of people, Starbucks is the synonym of coffee. So essentially, it isn’t an exaggeration to say its business relies on a mental association between a logo and a need for coffee. That’s how powerful brand awareness is.
And the amazing part is, however absurd this may sound, the Starbucks logo has nothing to do with coffee. Starbucks has even dropped the word “coffee” from the logo.
How to measure
Measuring brand awareness is the domain of specialized research companies. A common method for measuring it is through surveys. However, this option has its flaws: It’s expensive and time-consuming.
Alternatively, you can gauge the overall trend of your brand awareness yourself using online tools. The only caveat is this method will give more accurate estimations for online businesses than the predominantly offline ones.
You can also use a keyword research tool to discover the search volume of your brand name. The reason is this: If your brand awareness increases, more people will want to buy from you and look up your brand on the web.
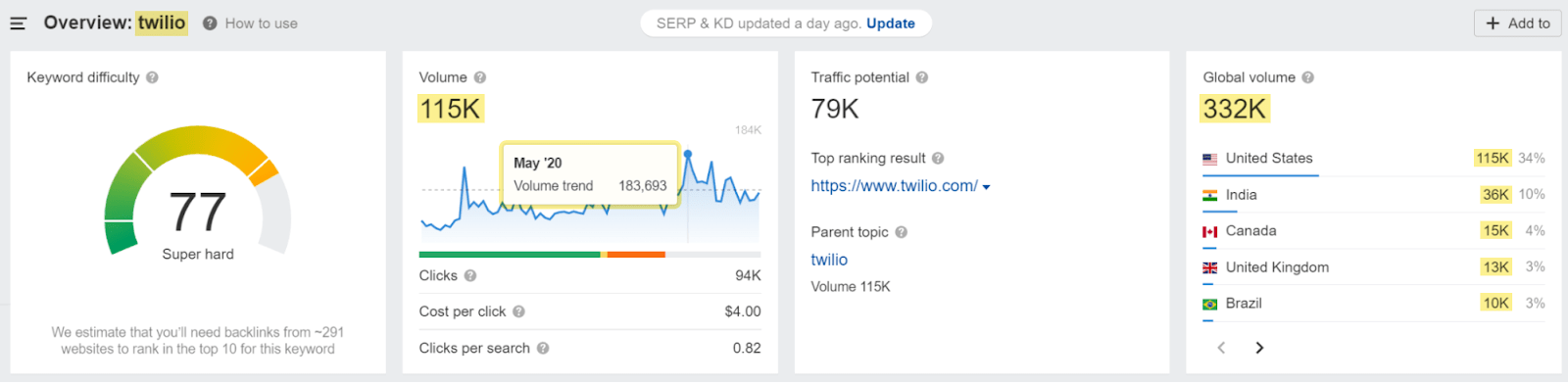
For example, if you use Ahrefs’ Keywords Explorer, you can just plug in your brand name and instantly get:
- The number of estimated monthly searches for a specific country (and globally).
- A graph of monthly searches plotted in time that offers quick insights into trends.
You can also easily measure your performance against your competitors’ (technically, this kind of comparison is called measuring the share of voice).
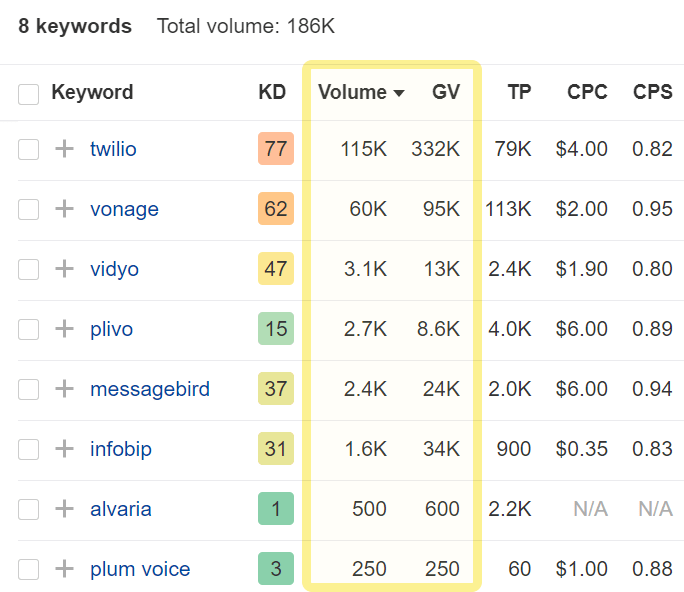
If you’re not an Ahrefs user or just need a point of reference without the search volume data, you can use Google Trends to gauge interest in branded queries.
So far, we’ve discussed rather indirect ways to increase revenue. Now, we’ll discuss three ideas for increasing revenue directly.
The first way is revising your pricing. If you have solid reasons for thinking you’re not charging enough for the value you provide, you can try to increase prices. Even a price increase of a few percent can result in significant returns if multiplied by hundreds or even thousands of new customers. Word of advice: A good practice here is to keep the original price for any existing customers.
A seemingly counterintuitive way (also quite risky) to increase your profits is through lowering prices (e.g., penetration pricing, loss leader strategy). This can lower the barrier enough for the arrival of new customers (you can even win your competitors’ customers this way).
Recommended reading: How to Increase SaaS Prices the Right (and Profitable) Way
The second way is adding new services and/or products. For instance, a dog food brand decides to expand its assortment by offering dog accessories like toys, dog care products, or beddings. It can even create special product bundles and call it “new dog owner essentials.”
The third way is cross-selling and upselling. Cross-selling means suggesting other products in addition to the chosen product. Upselling suggests a more expensive version of the chosen product.
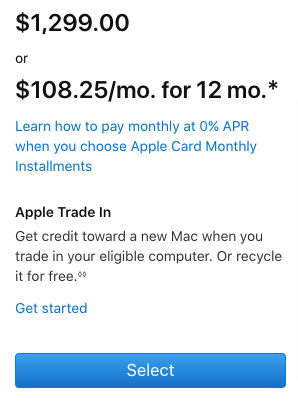
Let’s learn from the best here. When you’re shopping for a new iMac, you will first see a standard price for the product:
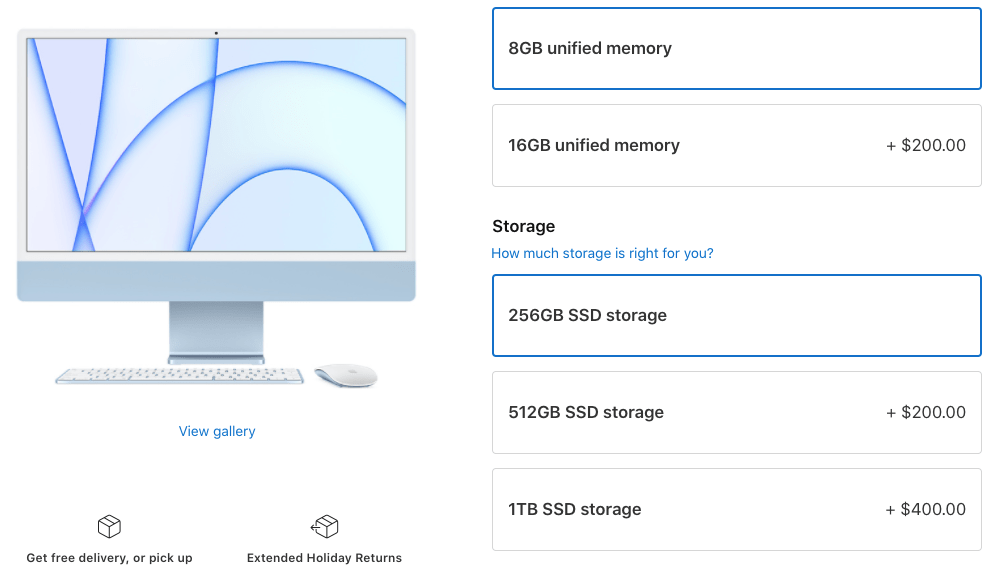
Then you will be offered an array of upsell options:
Followed by an even wider array of cross-selling suggestions:

How to measure
The easiest way to measure revenue is to measure the number and the value of sales. But a lot of companies also need to measure recurring revenue from subscriptions, the revenue growth rate, and the value of each new customer.
Recurring revenue
Monthly recurring revenue (MRR) measures how much you’re earning each month through recurring contracts (i.e., subscriptions).
MRR = number of subscribers on a monthly plan * average revenue per user
For annual plans, you have to divide the plan price by 12 and then multiply by the number of customers on that plan.
For example: If you have 700 customers on a $9 per month plan and 100 customers on a $97 yearly plan, your MRR will be:
(700 x $9) + ($97/12 x 100) = $7,108 MRR
If you want to track annual recurring revenue (ARR) as well, all you need to do is multiply MRR by 12.
In our example, that is:
$7,108*12 = $85,296 ARR
Revenue growth rate
Revenue growth rate measures the month-over-month percentage increase in revenue. This metric is an indicator of how quickly your company is growing.
You can measure the revenue growth rate for any period you need: weeks, months, or years.
Let’s say you want to measure the annual growth rate compared to the previous year. The formula for that will be:
(revenue year 2 — revenue year 1) / revenue year 1 x 100 = revenue growth rate (%)
In our example, that is:
($170,592 — $85,296) / $85,296 x 100 = 100% revenue growth rate
Customer lifetime value
Customer lifetime value (CLV) is the total worth of a customer to a business over the whole period of their relationship. CLV can also be used as a predictive metric of how much revenue each new customer will bring on average.
There are multiple models of calculating CLV. Without going into too much detail about each alternative, here’s a fairly simple formula to calculate CLV:
customer lifetime value = average order value x purchase frequency rate x average customer lifetime
Where:
- Average order value is your total revenue divided by the number of purchases.
- Purchase frequency rate is the total number of purchases divided by the number of customers.
- Average customer lifetime is the number of days between the first and last purchase date, divided by 365.
Final thoughts
Marketing goals, by nature, are usually grand and ambitious. Hence, they can be quite intimidating.
But no worries. You can overcome that problem by setting achievable goals and breaking your overarching goal into smaller bits. You can see how it’s done in practice using SEO goals as an example in the below article:
Got questions? Ping me on Twitter.